



السمعة:
- إنضم7 فبراير 2024
- المشاركات 52
- مستوى التفاعل 108
- النقاط 33
بسم الله الرحمن الرحيم
و الصلاة والسلام على اشرف المرسلين سيدنا محمد
السلام عليكم ورحمة الله تعالى وبركاته
مرحبًا بكم من جديد في رحلتنا بتعلم الالة!
لقد راينا في الدورة السابقة نظرة عامة عن تعلم الآلة , انواعه والفكرة الاساسية في بناء نماذج ذكاء اصطناعي لكن اليوم سننتقل من النظري الى التطبيق الفعلي لفهم افضل واكثر عمقا
ماهو هدفنا من هذه الدورة ?
هدفنا اليوم هو بناء نموذج كامل من الصفر مع التركيز على كل خطوة اساسية وتغطية جميع المفاهيم والمصطلحات المهمة التي تحتاجوها للبدء في بناء النماذج مهما كنت مبتدئا.
لذا هل انت مستعد للخوض في هذه الرحلة والانتقال لمستوى اعلى ? , لننطلق اذًا

اليوم سننشئ نموذج تعلم الة خاص في مرضى داء السكري بحيث يقرر هذا النموذج ما ان كان هذا الشخص مصابا ام لا وهذا طبعا وفق مجموعة من البيانات المتعلقة بهذا الشخص
لذا لنشرع في خطوات بناء نموذج ذكاء اصطناعي
في تعلم الالة لدينا 7 خطوات اساسية معترف بها عالميا قد تختلف من شخص الى اخر لكن من دون هذه الخطوات سيكون اداء النموذج ضعيفا وغير موثوق
خطوات بناء نموذج تعلم الالة (Machine learning model )
 جمع البيانات (Data collection )
جمع البيانات (Data collection )  :
:
تعد عملية جمع البيانات خطوة حاسمة في انشاء نموذج التعلم الالي حيث يتم جمع البيانات ذات الصلة من مصادر مختلفة لتدريب النموذج وتمكينه من اجراء قرارات وتوقعات دقيقة كما ان موثوقية ودقة هذه البيانات سيكون لها تاثير كبير على اداء ودقة النموذج الخاص بنا وهذا لان الهدف الاساسي من كل نموذج هو جلب له كمية كبير من البيانات التي يقوم بالتعلم والتدرب عليها فطبعا لو كانت هذه البيانات غير دقيقة او متناقضة سيؤثر هذا سلبا على النموذج البيانات التي يتم جمعها يمكن أن تاتي في عدة أشكال، مثل:
- ملفات CSV أو Excel
- صور

- قواعد بيانات SQL

- ملفات JSON أو XML

يمكن جمع البيانات من عدة مصادر اشهرها
 Kaggle: يحتوي على مجموعة ضخمة من البيانات المفتوحة ويُعتبر مصدرًا موثوقًا. Google Dataset Search: محرك بحث قوي للعثور على مجموعات بيانات متنوعة. UCI Machine Learning Repository: أحد أقدم وأشهر مستودعات البيانات الأكاديمية.
Kaggle: يحتوي على مجموعة ضخمة من البيانات المفتوحة ويُعتبر مصدرًا موثوقًا. Google Dataset Search: محرك بحث قوي للعثور على مجموعات بيانات متنوعة. UCI Machine Learning Repository: أحد أقدم وأشهر مستودعات البيانات الأكاديمية.الان كيف نختار بيانات مناسبة ? :
كما اخبرتكم في البداية سنقوم بانشاء نموذج يتوقع ما إن كان شخص معين مصاب بداء السكري ام لا وفقا لمجموعة من البيانات الخاصة بهذا الشخص
انا استعملت هذه البيانات تجدونها في الرابط التالي شخصيا لا اراها بيانات دقيقة جدا لكنها تفي بالغرض
عند التعامل مع بيانات طبية يفضل التأكد من أن البيانات تمت مراجعتها والموافقة عليها من قبل مختصين في المجال الطبي خاصة إذا كنت تخطط لاستخدام النموذج تجاريا أو بيعه لشركة طبية.
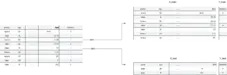
كما ترون في الصورتان الموضحتان اعلاه لدينا جدول ضخم يحتوي على مجموعة من البيانات الخاصة بكل شخص كمستوى الهيموغلوبين في الدم او تاريخ الشخص في التدخين وغيرها يمكنكم الاطلاع وفهم تفاصيل الاعمدة اكثر في الرابط التالي ستجدون شرحا لهم كلهم , والصورة على اليسار سترون عمود باسم diabetes هذا العمود يخبرنا
ما اذا كان الشخص مريض ام لا ( 0 لغير المريض و 1 للمريض ) وهذا ماتكلمنا عنه في الدورة السابقة فيما يخص انواع تعلم الالة ,بما ان هذا المشكل يحتمل نتيجتين فقط 0 او 1 اذا هذا النوع من تعلم الالة ينتمي الى التعلم بالاشراف (supervised learning ) وبالتحديد مشكلة من نوع التصنيف (Classification problem).
اذا بهذا انتهينا من الخطوة الاول وجمعنا البيانات التي نحتاجها والان بداية من الخطوة التالية سيبدا التطبيق الحقيقي .
ملاحظة : يفضل ان يكون لديك معرفة مسبقة بلغة بايثون واذا لم يكن لديك فلا مشكلة ساحاول شرح جميع التعليمات البرمجية :
تنبيه مجال تعلم الالة قد يختلف عن مجالات اخرى كبرمجة التطبيقات وغيرها فهو مجال نظري بحت فعلى الشخص ان يكون لديه اساس قوي جدا لان مرحلة البرمجة في انشاء النماذج هي اسهل شيئ لانه ببساطة كل شيئ مجهز مسبقا فما عليك سوى التطبيق كما انه سيساعد على تحليل المشاكل بشكل افضل وادق
 معالجة البيانات وتنظيفها (Data preprocessing )
معالجة البيانات وتنظيفها (Data preprocessing )  :
:
تتضمن هذه المرحلة العديد من الخطوات وهي كالتالي :
التعامل مع القيم المفقودة (Missing Values)تطبيع البيانات (normalisation ) تحويل البيانات الى قيم محصورة بين 0 و1 لزيادة الدقة وتقليل نسبة الخطا تحويل القيم الحرفية الى قيم عددية(encoding categorical variables ) ,فالالة تعتمد على لغة الارقام لذا بالتاكيد عند تحويل جميع البيانات الى قيم عددية سيزيد من الدقة والاداءولنبدا في معالجة الـ dataset الخاصة بنا
اولًا: علينا تحميل البيانات الى المحرر الخاص بنا يمكنكم استعمال pycharms او jupiter note book او vs code او google colab
شخصيا استعمل google colab وهو عبارة عن بيئة سحابية مجانية تتيح لك كتابة كود python ونتفيذه مباشرة على المتصفح دون الحاجة لتثبيت اي شيئ على جهازك يستعمل كثيرا من قبل المطورين لانه يوفر امكانية تشغيل الاكواد على gpu او cpu لان بناء نماذج يستهلك الكثير من موارد الحاسوب لذا يفضل استعماله اذ كان لديك جهاز بمواصفات ضعيفة .
يمكنكم تحميل البيانات الخاصة بداء السكري من الرابط اعلاه ستكون على شكل ملف csv
اولًا قومو بفتح google colab وقومو بالضغط على new notebook in drive <-file
بعدها اضغطو على file ثم على الزر المؤطر بالازرق وقومو باستوارد ملف csv الذي حملتموه من kaggle
يمكنكم كتابة الاكواد الاطار المكتوب بداخله start يمكنكم ايضا تنفيذ كل تعليمة على حده على سبيل مثال اذا كتبت كود داخل ذلك الاطار ثم ضغط على +code سيظهر لك تلقائيا اطار اخر لكتابة الكود فيه ايضا ما احاول توصيله انه اذا اردت تفيذ الكود لا تحتاج تنفيذ كل شيئ من بداية يكفي فقط تنفيذ ماكتبته داخل الاطار ,ساوضح لكم اكثر
اولا لنقم باستوراد بعض المكاتب المهمة التي سنحتاجها في عملنا اضافة الى تحميل البيانات لامكانية التعديل عليها
اذًا كما اخبرتكم الاطار الاول قمت باستوراد فيه مكتبتي numpy والتي هي عبارة عن مكتبة متخصصة في العمليات الرياضية والتعامل مع المصفوفات متعددة الابعاد
اما pandas هي مكتبة قوية لمعالجة البيانات كحالتنا هذه توفر المكتبة هياكل بيانات مثل excel وdataframe وjsonوsql وغيرها
اما الاطار الثاني الخاصة بتحميل البيانات (load the dataset ) ,قمنا بتهيئة متغير باسم df والذي سنخزن فيه البيانات الخاصة بنا وبما ان pandas يساعدنا في تعامل مع هياكل البيانات المختلفة سنوقم ببساطة بكتابة pd.read_csv("اسم الملف الذي حملته بالكاملة ") ,pd اختصار لpandas لانني كتبت import pandas as pd لاختصار الكتابة فقط .
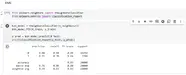
اذا اردنا طباعة dataframe الخاصة بنا نكتب فقط اسم المتغير اعلاه df.head() وكما ترون قد تم عرض البيانات الخاصة بنا .
تحليل البيانات :
الان تاتي خطوة تحليل البيانات سنبدا من التحقق ما اذا كانت البيانات الخاصة بنا نظيفة ام لا :
نلاحظ على سبيل المثال في عمود smoking_history وجود قيمة باسم No Info والمقصود بها null وهذه احدى الاشياء التي تكلمنا عنها بالاضافة الى وجود قيم حرفية في نفس العمود وايضا في عمود gendre
كما نلاحظ ان الفرق بين القيم كبير نسبيا انظرو الى عمود blood _glucose_level ففي السطر رقم 0 نجد 140 ثم في السطر 2 تنزل الى 80 وهكذا ومازال لدينا 8000 الف سطر زيادة , و هه قد تتسائلون كيف بامكاننا قراءة كل هذا الكم الهائل من البيانات لكن لاتقلقو فمع python ستصبح حياتكم اسهم

كود:
print('our dataset shape :',np.shape(df)) #هنا نطبع شكل المصفوفة الخاصة بنا عن طريقة مكتبة numpy
# نكتب فقط np.shape(اسم dataframe=df)
# النتيجة هي :
our dataset shape : (100000, 9)
# اي لدينا 100000 سطر مع 9 اعمد فقط
كود:
print(df.isnull().sum()) # مايعني قم بحساب مجموع كل القيم المفقودة لك عمود
# النتيجة هي :
gender 0
age 0
hypertension 0
heart_disease 0
smoking_history 0
bmi 0
HbA1c_level 0
blood_glucose_level 0
diabetes 0
dtype: int64ستلاحظون هنا انه لا يوجد قيم مفقودة لكن مما سبق قلنا ان قيمة No Info تعتبر قيمة مفقودة في عمود smoking_history وهذه احد الاخطاء الموجودة في هذه البيانات
الان اذا اردتم معرفة unique values لكل عمود نكتب الكود التالي :
سيساعدنا هذا في معرفة ما اذا كان العمود يحتوي على قيم حرفية ام لا
كود:
for x in df.columns :
df[x].unique()
print("Unique values:", df[x].unique())
# النتيجة هي :
Unique values: ['Female' 'Male' 'Other']
Unique values: [80. 54. 28. 36. 76. 20. 44. 79. 42. 32. 53. 78.
67. 15. 37. 40. 5. 69. 72. 4. 30. 45. 43. 50.
41. 26. 34. 73. 77. 66. 29. 60. 38. 3. 57. 74.
19. 46. 21. 59. 27. 13. 56. 2. 7. 11. 6. 55.
9. 62. 47. 12. 68. 75. 22. 58. 18. 24. 17. 25.
0.08 33. 16. 61. 31. 8. 49. 39. 65. 14. 70. 0.56
48. 51. 71. 0.88 64. 63. 52. 0.16 10. 35. 23. 0.64
1.16 1.64 0.72 1.88 1.32 0.8 1.24 1. 1.8 0.48 1.56 1.08
0.24 1.4 0.4 0.32 1.72 1.48]
Unique values: [0 1]
Unique values: [1 0]
Unique values: ['never' 'No Info' 'current' 'former' 'ever' 'not current']
Unique values: [25.19 27.32 23.45 ... 59.42 44.39 60.52]
Unique values: [6.6 5.7 5. 4.8 6.5 6.1 6. 5.8 3.5 6.2 4. 4.5 9. 7. 8.8 8.2 7.5 6.8]
Unique values: [140 80 158 155 85 200 145 100 130 160 126 159 90 260 220 300 280 240]
Unique values: [0 1]
# x عبارة عن متغير ياخذ قيمة كل عمود بالترتيب عبر كل تكرار في الحلقة ففي التكرار الاول سياخذ قيمة gender
# اما df[x].unique() اي القيمة الفريدة الخاصة بالعمود x
# ستكون بهذا الشكل اثناء التنفيذ df['gender'].unique()
وكما ترون لقد تحصلنا على القيم الفريدة الخاصة بكل عمود على الترتيباما اذا اردتم رؤية نوع البيانات وحجمها واستهلاكها للذاكرة يمكنكم فقط كتابة ()df.info وستحصلون على التالي :
كود:
df.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 100000 entries, 0 to 99999
Data columns (total 9 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 gender 100000 non-null object
1 age 100000 non-null float64
2 hypertension 100000 non-null int64
3 heart_disease 100000 non-null int64
4 smoking_history 100000 non-null object
5 bmi 100000 non-null float64
6 HbA1c_level 100000 non-null float64
7 blood_glucose_level 100000 non-null int64
8 diabetes 100000 non-null int64
dtypes: float64(3), int64(4), object(2)
memory usage: 6.9+ MBالاستنتاج :
الان نستنتج من كل هذا التالي :
العمودان gender وsmooking_history يحتويان على بيانات حرفية والتي يجب تعويضها باخرى رقمية في العمود الخاص بالgender نلاحظ قيمة غريبة باسم Others والتي يجب التخلص منها كوننا مسلمين طبعا ساعتبرها في هذه الحالة قيمة مفقودة اما قيم No Info ساعتبرها قيمة حرفية عادية لانه يوجد فقط 3000 قيمة منها فلن تؤثر بشكل كبير يمكنكم حسابها عن طريق التعليمة التالية : ()df['smoking_history'] == 'No Info'.sum وجود فرق كبير بين القيم
وجود فرق كبير بين القيم الحل :
لنبدا مع العمود gender ,لدينا 3 حلول اما ان نقوم بحذف كل الاسطر التي تحتوي على قيمة (feature) باسم other اذا كان عدد ظهوره قليل جدا مقارنة بFemale وMale
او نقوم بتعويض قيمة Other بالقيمة الاكثر ظهورا فلو كانت على سبيل المثال قيمة Female اكثر ظهورا من Male عندها نعوض Other بFemale
والحل الاخير تحويل Other الى فئة مستقلة على سبيل مثال نعطي للMale قيمة 0 وFemale 1 وOther قيمة 2
لكن انا اريد التخلص منها لذا سنطبق اما الحل الاول او الثاني لنقم بتحليل البيانات ونقرر
كود:
print("number of male ",(df['gender']=="Male").sum())
print("number of female",(df['gender']=="Female").sum())
print("number of other",(df['gender']=="Other").sum())
# النتيجة هي :
number of male 41430
number of female 58552
number of other 18تطبيق الحل الاول كالتالي :
كود:
df = df[df["gender"] != "Others"]
# لنبدا بقراءة التعليمة من الداخل اذا كان df[gender] لا يساوي other سيتم ضمنه داخل df الكبيرة
# اي انه سيقوم بوضع جميع الاسطر داخل dataframe ماعدا الاسطر التي تحتوي على other
كود:
df['gender'] = df['gender'].apply(lambda x:"Female" if x == 'Other' else x)
print(df['gender'].unique())
# هنا نقوم بتطبيق دالة apply والتي ستتحقق من كل قيمة في العمود gender
# كما ترون سنعوض x بfemale اذا كان x==other
# اما else x معناها يبقى كما هو ثم في الاخير سنطبق هذه التغيرات اعلى العمود الاصلي
اي نقوم بdf[gender]=....
df["gender"] = (df["gender"] == "Female").astype(int)
اما هنا فنحن نطلب منه تحويل كل قيمة فريدة الى رقم اي سيصبح لدينا قيمتين 1 و0 في العادة لا نستخدم هذا لكن في هذه الحالة ليس هناك مشكلة
print(df['gender'].unique())
النتيجة :
our new unique values ['Female' 'Male']
[1 0]ننتقل الان الى العمود smoking_history ونقوم بتحويل القيم الحرفية الى قيم عددية هناك الكثير طرق لكني ساستعمل طريقة واحدة فقط لانها اكثر فعالية في هذا المشكل
الطرق الاكثر استعمالا هي labelEncoder حيث تقوم بتعويض كل قيمة فريدة برقم فريد فلو كان لدينا خمس قيم مختلفة سترقمهم من 0 الى 5
والطريقة التي افضلها هي oneHotEncoder حيث تقوم بتحويل كل قيم فريدة الى عمود بالكامل ساعطيكم مثال :
انظرو للفرق في الطريقة الاول تم منح كل طعام رقم مخصص لها من 1 الى 3 اما الطريقة الثانية قمنا بتخصيص عمود كامل لكل قيمة هذه الطريقة فعالة جدا خاصة انها تضمن ان جميع القيم اما 0 او 1 لكن عيبها الوحيد هو لو كان لدينا عدد هائل من unique values عدد بالالاف تخيلو معي فقط كم سيكون حجم الجدول حينها
لكن في مشكلتنا هذه عدد unique values لايتخطى 7وهو ليس بالعدد الكبير ابدا لذا لنقم بنتفيذها
كود:
from sklearn.preprocessing import OneHotEncoder # استرداد الخوارزمية من مكتبة تالية وهي عبارة عن مكتبة كبيرة
# بها اشهر خورازميات تعلم الالة كما انها جاهزة مسبقا ليس عليك انشاء الخوارزمية من الصفر
encoder = OneHotEncoder() # اختيار خوارزمية OneHotEncoder() وضمنها داخل المتغير encoder
encoded = encoder.fit_transform(df[['smoking_history']]).toarray()
# تحويل البيانات إلى DataFrame مع أسماء الأعمدة الجديدة
encoded_df = pd.DataFrame(encoded, columns=encoder.get_feature_names_out(['smoking_history']))
# حذف العمود الأصلي ودمج البيانات الجديدة
df = df.drop(columns=['smoking_history'])
df = pd.concat([encoded_df, df.reset_index(drop=True)], axis=1)الان يجب فهم اهم جزئية في تطبيق الخوارزميات في بايثون الا وهي دالتي fit وtransform ولتبسيط الامر لاكبر قدر ممكن دالة fit تقوم بتخزين وتحديد القيم الفريدة في هذا المثال ستقوم بتخزين وتحديد القيم الفريدة لهذا العمود ففي في خلف الكواليس fit يقوم بانشاء قاموس للقيم الفريدة تخيلوها بهذا الشكل
كود:
{
'current', 'No Info', 'former', 'never', 'ever', 'not current'
}هذه القيم تحدد ترتيب الاعمدة في تشفير
ثم ياتي دور transform() للقيام بتغييرات التي تحدثنا عنها فياخذ كل قيمة في العمود ويحولها الى مصفوفة ثنائية مكون من 1 و0 وهذا بناءا على القيم الفريدة التي حفظها fit
| الفئة الاصلية | المصفوفة الناتجة | |
|---|---|---|
| never |
| |
| former |
| |
| current |
| |
| ever |
| |
| not current |
| |
| No info |
|
لاحظ أن كل صف يحتوي على قيمة واحدة تساوي 1، والباقي أصفار (One-Hot Encoding).
لنشرح الكود اذا كما اخبرتكم بعد التعليمة الاولى ثم ينفذ التعليمة ثانية وهذا مايحصل خلف الكواليس
encoded_df = pd.DataFrame(encoded, columns=encoder.get_feature_names_out(['smoking_history']))
اما هذه التعليمة فببساطة تقوم باعطاء اسم لكل عمود جديد تحصلنا عليه تلقائيا بحيث اسم العمود سيكون كالتالي : اسم العمود الاصلي زائد اسم القيمة مثلا العمود الاول باسم smoking_history_never
df = df.drop(columns=['smoking_history']) هذه التعليمة تقوم بنزع العمود الاصلي من dataframe لاننا لم نعد نحتاجه
اما هذه
df = pd.concat([encoded_df, df.reset_index(drop=True)], axis=1) تقوم بالصاق الاعمدة الجديدة مع dataframe الخاص بنا افقيا اي على طول الصفوف axis=1 يعني افقيا
يمكنكم كتابة df لرؤية الناتج والذي هو كالتالي :
كما ترون لقد تحصلنا على النتيجة المروجة حتى بالنسبة للعمود gender فقط لايظهر هنا وهذا بسبب زيادة عدد اعمدة المصفوفة من 9 الى 13
هناك شيئ فقط لم اتكلم عنه وهذا لعدم ظهوره هنا بشكل مباشر وهو كيفية التخصل من القيم المفقودة يمكن حل هذه المشكلة بالعديد من الطرق لكن اشهرها هي طريقة متوسط القيم او Average/Mean Imputation حيث نقوم بتعويض القيم المفقودة بمتوسط القيم الاخرى في نفس العمود
اليكم الصيغة الرياضية لها :
Mean=∑Xi/Nvalide
Xi:تشير الى القيم الغير المفقوة Nvalide: عدد القيم المفقودة
ببايثون ستكون بهذا الشكل :
كود:
df['column_name'].mean()
# يستم هنا نزع القيم المفقودة تلقائيا في العمود المحددالان تقريبا قد انتهينا من تنظيف بياناتنا مايبقى سوى خطوة واحدة واخيرة الا وهي التطبيع (Normalisation ),يفضل القيام بهذه الخطوة في مرحلة preprocessing لكن انا استعملتها فقط في المرحلة الرابعة والتي سنراها فيما بعد , هكذا نكون قد انتهينا من المرحلة 2 ومنه يمكننا الانتقال للمرحلة التي بعدها
تقسيم البيانات (Data spliting) :
 بيانات التدريب (Training set) : والتي تستخدم لتدريب النموذج بيانات الاختبار (Testing set ): تستخدم لاختبار دقة النموذج بعد التدريب
بيانات التدريب (Training set) : والتي تستخدم لتدريب النموذج بيانات الاختبار (Testing set ): تستخدم لاختبار دقة النموذج بعد التدريب بحيث يجب علينا اتباع القاعدة التالية : وهي تخصيص 80% من البيانات الاصلية للتدريب و20% المتبقية ستكون مخصصة للاختبار ,ولمن لم يفهم بعد يمكنه العودة الى الدورة السابقة لفهم كيفية تقسيم البيانات والفائدة من التقسيم ,اذا فلنبدا بتقسيم البيانات ساقوم بتقسيم البيانات بطريقتين وهما عن طريق الكود و الرسم
تمثيل تقسيم البيانات :
كما ترون نقسم البيانات الى قسمين التدريب والاختبار ,حيث يتم فصل عمود labels (هو العود الذي يتم فيه تصنيف الشيئ سواءا في هذه الحالة او غيرها اما باقي الاعمدة تسمى بالfeutures) لذا بيانات التدريب يصبح لها قسمين الاول يسمى بها X_train والذي يتحوي فقط على الميزات ام القسم الثاني Y_train يحتوي على حالة الشخص لكل سطر من الميزات ونفس الشيئ ينطبق بالنسبة لبيانات الاختبار .
ستتسائلون ماالفائدة من هذا اولا عندما يتدرب النموج على بيانات التدريب المعطاة سنقوم فيما بعد باختبار دقة النموج بحيث اننا سنمنحه فقط X_test ويصنف هو وحده ما ان كان شخص مريض ام لا ثم نقارن تلك النتيجة بY_test ونقيس الدقة اتمنى ان الفكرة اصبحت واضحة لكم .
تقسيم البيانات باستخدام بايثون :
كود:
train,test=train_test_split(df,test_size=0.2,random_state=42)
np.shape(train)#---> =(80000,14)كل ماقمنا به هو انشاء متغيرين train وtest ثم باستخدام الدالة split قسمت df بحيث منحت 0,2 اي 20% لبيانات الاختبار اما باقي البيانات ستمنح تلقائيا للtrain
ملاحظة: هنا لم اقم بتقسيم train الى x_train وy_train بعد وهذا لاني اريد اجراء بعض الاختبار عليهم قبل التقسيم النهائي
نعود للمرحلة السابقة وبالضبط خطوة scaling او normalisation التي تكلمنا عنها حيث سنقوم الان بتطبيع البيانات لكل من train وtest بعدها نقوم بتقسيمهم كما هو موضح في الصورة اعلاه ,يمكنكم تطبيع البيانات قبل التقسيم ثم اجراء عملية التقسيم ليست هناك اي مشكلة
لتطبيع البيانات هناك العديد من الخورزميات التي يمكن استعمالها ك :
Min-Max Scaling (التطبيع الأدنى-الأقصى) Z-Score Normalization (التقييس - Standardization) Robust Scaling (التطبيع القوي)مبدئيا سنقوم باستعمال الخورزمية الاولى لسهولتها اما باقي الخوارزميات ستورنها في دورة مخصصة فقط لشرح كل انواع خورازميات التعلم انشاء الله
شرح خوارزمية MIN-Max Scaling :
الفكرة:يتم تحويل كل قيمة الى نطاق معين عادة مايكون بين 0 او1
اليكم الصيغة الرياضية التالية :
( Xman - Xmix)/X'=(X - Xmin)
حيث:X: القيمة الأصلية (قبل التطبيع).
Xmin : أصغر قيمة في العمود الذي نقوم بتطبيعه.
Xmax : أكبر قيمة في العمود الذي نقوم بتطبيعه.
X′ : القيمة بعد التطبيع، والتي ستكون بين 0 و 1.
لنحاول برمجتها باستخدام بايثون الان وكالعادة سنقوم باستيراد الخورازمية فقط لانها جاهزة مسبقا
كما ساقوم ايضا بتقسيم train الى x_train وy_train وtest الى x_test وy_test
كود:
from imblearn.over_sampling import RandomOverSampler
def scaling(df,op=False):
X = df[df.columns[:-1]].values# اولا نقوم بوضع كل الاعمدة من المؤشر 0 الى المؤشر ماقبل الاخير
# علامة : يمكنكم اعتبارها كحلقة تمر على كل الاعمدة تلقائيا
y = df[df.columns[-1]].values# اما هنا نقوم بوضع العود الاخير في y
scaler = MinMaxScaler()# اما هنا نقوم بتضمين الخوارزمية داخل scaler
X = scaler.fit_transform(X)# هنا نقوم بمنادات الدالة fi_transform التي شرحناها مسبقا
data = np.hstack((X, np.reshape(y, (-1, 1))))
هي اختصار لـ np.hstack horizontal stack أي دمج المصفوفات أفقيًا (جنبًا إلى جنب)
return data, X, y
train, X_train, y_train = scaling(train)#function call
test, X_test, y_test = scaling(test)#function callلنحاول شرح الكود اكثر X هي المصفوفة التي تحتوي على البيانات المستقلة (features) بعد تطبيق MinMaxScaler اما y هي القيم المستهدفة (labels) تكون ذات بعد واحد (vector) ,np.reshape(y, (-1, 1)) يقوم بتحويل y إلى مصفوفة ذات بعدين بحيث يكون كل عنصر في عمود منفصل
عند استخدام np.hstack يتم دمج X و y بحيث تصبح y العمود الاخير في المصفوفة الجديدة مثال :
كود:
X = np.array([
[0.1, 0.2],
[0.3, 0.4],
[0.5, 0.6]
])
y = np.array([1, 0, 1])
y_reshaped = np.reshape(y, (-1, 1))
data = np.hstack((X, y_reshaped)) #دمج البيانات افقيا
print(data)
النتيجة :
[[0.1 0.2 1. ]
[0.3 0.4 0. ]
[0.5 0.6 1. ]]بعد ذلك نقوم ارجاع القيم (return )
نقوم بانشاء ثلاث متغيرات train ,x_train ,x_train وننادي دالة scaling بحيث تاخذا مدخلا واحد الا و هو بيانات train الخاصة بنا
في النهاية عندما تقوم الدالة بreturn ستتغير بيانات train بسبب استعمال تقنية MaxMinscaler اضافة الى تقسيم البيانات ووضعها في x_train وy_train
ثم نعيد نفس الشيئ مع بيانات test
بهذا لقد قمنا تماما بالموضح في الصورة الخاصة بتقسيم البيانات
هكذا نكون قد انتهينا من مرحلة التقسيم
بمجرد وصولكم لهذا المرحلة فيمكنكم القول انكم وصلتم الى 80% من حلك للمشكلة فهذه المراحل هي الاساسية وخاصة مرحلة data preprocessing تعتبر هي الاكثر الاهمية
 اختيار النموذج (Model Selection) :
اختيار النموذج (Model Selection) :
يعد ايضا اختيار الخوارزمية المناسبة احد اكثر التحديات الي تواجهك فليس هناك طريقة بحد ذاتها تخبرك بالخوارزمية التي عليك استعمالها ,فيرجع الامر الى خبرتك في بناء النماذج ومدى فهمك للبيانات والعديد من الامور ,فعلى الشخص تقييم تعقيد واداء كل خوارزمية وقابليتها للتفسير يمكننا استخدام طرق اكثر فعالية وضمانا مثل التعلم العميق لكنه معقد جدا ويطول شرحه كثيراااا اضافة الى ان مضوعنا هو تعلم الالة .
كما نعرف هذه البيانات التي قمنا بالعمل عليها تنتنمي الى بيانات التصنيف هذا النوع من البيانات له العديد من الخورزميات المشهورة التي يتدرب عن طريقها نموذج التعلم الالي من اشهرها مايلي :
الانحدار اللوجستي (Logistic Regression) – نموذج بسيط لكنه فعال، خاصة في التصنيفات الثنائية.آلة المتجهات الداعمة (Support Vector Machine - SVM) – مفيدة للتصنيفات الثنائية ومتعددة الفئات باستخدام حدود قرار غير خطية.شجرة القرار (Decision Tree) – تبني نموذجًا هرميًا لاتخاذ القرارات بناءً على السمات.الغابة العشوائية (Random Forest) – تعتمد على تجميع عدة أشجار قرار لتحسين الدقة وتقليل التحيز.خوارزمية K-الأقرب (K-Nearest Neighbors - KNN) – تصنف نقطة جديدة بناءً على فئات أقرب K جيران لها.نايف بايز (Naïve Bayes) – يعتمد على نظرية الاحتمالات وهو فعال جدًا مع البيانات النصية والتصنيفات متعددة الفئات.بالنسبة لنا نحن سنختار خوارزمية k الاقرب فهذه الطريقة اثبتت فعاليتها بشدة في مشاكل التصنيف كما انها سهلة وبسيطة , لنبدا في فهم الية عمل هذه الخورازمية
الية عمل الخوارزمية KNN :
تحميل البيانات : تحتاج الخوارزمية إلى بيانات تدريبية تحتوي على سمات (Features) وفئات (Labels) اختيار قيمة K : يتم تحديد عدد الجيران الأقرب (عادة عدد فردي لتجنب التعادل) حساب المسافة : عند تقديم نقطة جديدة يتم حساب المسافة بين هذه النقطة وجميع النقاط في مجموعة التدريب تحديد أقرب K نقاط :يتم اختيار أقرب K نقاط بناء على المسافة المحسوبة التصنيف حسب الأغلبية : تحسب الفئات الأكثر تكرارا بين الجيران ويتم تعيينها للنقطة الجديدة
التصنيف حسب الأغلبية : تحسب الفئات الأكثر تكرارا بين الجيران ويتم تعيينها للنقطة الجديدة طرق حساب المسافة في KNN:
يكون هذا عبر استخدام المسافة الاقليدية المشهروة والتي تحسب عبر العبارة التالية : انظرو لهذا تخيلو ان لدينا صنفين من البيانات الاول باسم positive review والثاني بnegative reviews الان اذا اضفنا مدخلا جديدا المسى في هذا الرسم ب query datapoint نريد تصنيف هذا المدخل لكننا لا نعرف ماذا نختار التصنيف الاول ام الثاني .
هنا ياتي دور knn فهو يحسب المسافة بين الجيران او النقط الاقرب له باستخدام عبارة المسافة الاقليدية ثم يختار الجيران الاقرب اي الاقل مسافة وهنا يجب على المستخدم اختيار عدد الجيران و ليكن K=3 حيث انه سيختار الجيران 3 الاقرب ثم يقرر اذا كان 2 منهم من اصل 3 تنتمي الى الفئة البنفسجية negative reviews اذا المدخل سيتم تصنيفه على انه negative reviews اما اذا كان 2 زرق من اصل 3 اذا المدخل سينتمي الى فئة positve reviws ببساطة والتي هي موضحة في الرسم after training .
قد تتسائلون لماذا يجب ان يكون K عدد فردي وليس زوجي ,يرجع هذا الى الخطوة التي سيتم تصنيف فيها المدخل فلو كان عدد الجيران المختار هو 4 سيختار اربع اقرب جيران مثلا 2 ثم ماذا بعدها سيجد فئتين بنفس العدد 2 من فئة positive و2 من فئة negative اي لهما نفس حظوظ الظهور فلن يتستطيع تصنيف المدخل هذا .
هذه هي خوارزمية KNN ارجو انكم استمتعتم بها فانا اعتبر هذه الخوارزمية احد امتع الخوارزمية
وبهذا نكون انتهينا من مرحلة اختيار النوذج .
تدريب النموذج (Model Training) :
لنحاول برمجة هذا الكلام ببايثون ,لاتنسو اننا سنقوم بتدريب النموذج باستعمال خوارزمية KNN
كود:
from sklearn.neighbors import KNeighborsClassifier # استيراد خورزمية knn من مكتبة sklearn
knn_model = KNeighborsClassifier(n_neighbors=5) كالعادة نقوم بتضمين الخوارزمية في مالتغير knn_model واختيار
عدد الجيران K=5
knn_model.fit(X_train, y_train) # نقوم بتدريب النموذج على البيانات xtrain وytrain
حيث انه سيخزن القيم الفريدة كما يحسب المسافة بين نقط
y_pred = knn_model.predict(X_test)
اما هذه فنحن نقوم بمنحها بيانات الاختبار لكن لا نمنحها Y_test
فنترك النموذج يتوقع القيم ويضعها في y_predالان بعدما انتهينا تدريب النموذج واختباره على بيانات الاختبار نكون قد انتهينا من هذه المرحلة ليتبقى مرحلة واحد اخير والتي هي
 تقييم النموذج (Model Evaluation):
تقييم النموذج (Model Evaluation): 
ستجدون شرح لكل المقاييس في الدورة السابقة
كود:
from sklearn.metrics import classification_report # تعتبر هذه مكتبة خاصة تستعمل في منحك تقرير كامل على نموذجك
من حيث الدقة والاداء وغيره
ثم نقوم ب
print(classification_report(y_test, y_pred))سنحصل على التالي :
1.دقة النموذج (Accuracy):
دقة التدريب: 0.97 (97%)
دقة الاختبار: 0.96 (96%)
الفرق بين الدقتين صغير جدا مما يشير إلى أن النموذج ليس لديه مشكلة فرط التكيف (Overfitting).
ملاحظة : مشكلة فرط التكيف هي مشكلة حيث ان النموذج يتعلم بيانات التدريب بشكل زائد بحيث يصبح اداؤه ممتازا على بيانات التدريب لكنه يفشل في التعميل على بيانات الاختبار يكمنك القول وكان النموذج يحفظ وحسب دون فهم ,وكما ترون عندما قسنا اداؤه على بيانات الاختبار تصحلنا على دقة 96 وهذا جيد
2-تقرير التصنيف (Classification Report):
الفئة 0 (Non-Diabetic)
الدقة (Precision): 96%
الاسترجاع (Recall): 99%
درجة F1: 98%الفئة 1 (Diabetic):
الدقة (Precision): 91%
الاسترجاع (Recall): 61%
درجة F1: 73%
تحليل للأداء:
النموذج يعمل بشكل جيد جدًا على الفئة "0" (الأشخاص غير المصابين بالسكري).
أداء النموذج على الفئة "1" (المصابين بالسكري) أضعف حيث الاسترجاع (61%) منخفض نسبيًا.
هذا يعني أن النموذج يفشل في التعرف على بعض المرضى المصابين بالسكري مما قد يؤدي إلى نتائج سلبية خاطئة (False Negatives).
المشكلة قد تكون بسبب توزيع البيانات (عدم التوازن بين الفئات) أو الحاجة إلى تحسين المعالجة المسبقة للبيانات.
الخلاصة:
النموذج دقته عالية بشكل عام ولكنه يعاني من ضعف في التعرف على المرضى المصابين بالسكري يمكن تحسين الأداء باستخدام تقنيات معالجة عدم التوازن وتحسين النموذج. تحسين النموذج (Model Optimization)
تحسين النموذج (Model Optimization) 
إذا لم يكن أداء النموذج جيدًا، نحتاج إلى تحسينه عبر: تحسين النموذج (Model Optimization) اعادة موازنة البيانات باستخدام طرق كoversampling وغيرها استخدام ميزات إضافية (Feature Engineering) لجعل النموذج أكثر دقة. زيادة حجم البيانات أو تحسين جودتها لتحسين التعلم.اعتذر لعدم شرحي للمرحلة جيدا لانها مرحلة تتطلب وقتا طويلا كما لها الكثير والعديد من الطرق ايضا الكثير من المصطلحات التي يجب فهمها
وبهذا نكون قد وصلنا الى نهاية رحلتنا في بناء نموذج تعلم الالة حيث استعرضنا جميع المراحل و الخطوات الاساسية بدءا من جمع البيانات وصولا الى تقييم ادائه وتحليله ,كما تعلمنا ان بناء نموذج قوي قد لايعتمد فقط على كتابة الكود بل يتطلب فهما عميقا للبيانات واختيار الميزات الصحيحة وضبط المعلمات لضمان افضل دقة
شكرًا لمتابعتكم، ونتمنى لكم التوفيق في رحلتكم مع تعلم الآلة! 
اراكم في الدورات القادمة انشاء الله
اراكم في الدورات القادمة انشاء الله
المرفقات

التعديل الأخير:
